SSR이 병목이 되었을 때
ECS 서비스에는 이미 Auto Scaling이 켜져 있었다. Task는 3개가 떠 있었고, Health Check도 통과하고 있었고, Load Balancer 타겟도 전부 정상이었다. 겉으로만 보면 트래픽 급증에 대비가 되어 있는 상태였다. 그런데 4월 6일 실제로 트래픽이 몰리자 서비스가 터졌다.
차트가 보여준 것
전체 상황은 apple-game-v2 클러스터의 web 서비스 ECS 대시보드에 그대로 나타나 있었다. Task 3개는 모두 실행 중이었고, Load Balancer 타겟도 3개 모두 정상이었다. 얼핏 보기에는 문제가 없어 보였다.
하지만 4월 6일, 예상치 못하게 SSR 서버에서 CPU 사용률이 거의 100%까지 치솟았다. Network TX도 대략 2.4 MB/s 수준까지 올라갔다. 반면 메모리 사용률은 10%대 중반에 머물러 있었고, 병목으로 보이지 않았다. 실제 문제가 될거라 생각했던 Gateway나 게임서버는 정상인데, 유저는 서버가 터져서 아무것도 못하는 상황이 생겼다. 이 와중에 Health Check는 계속 정상이라고 보고하고 있었다.
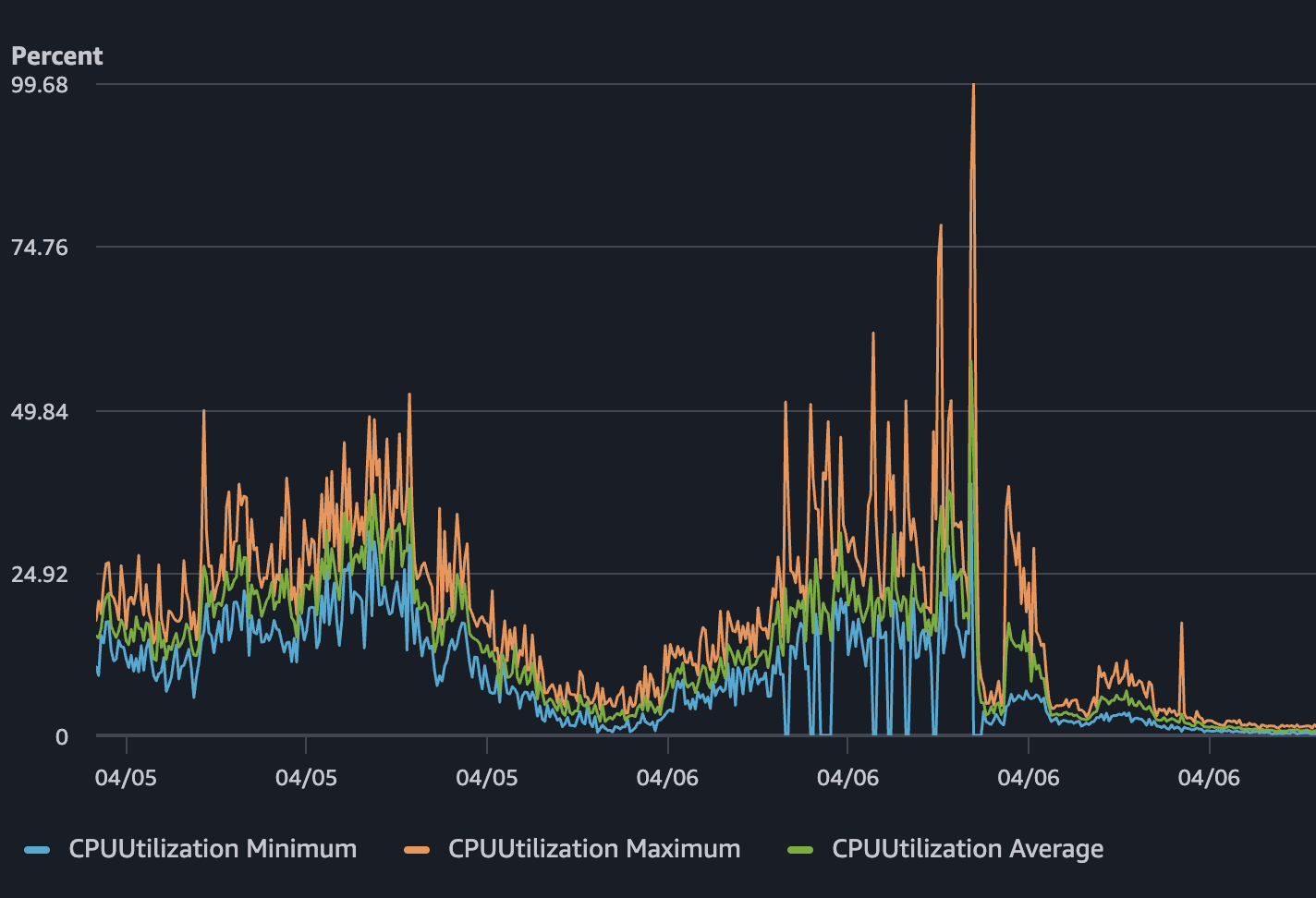
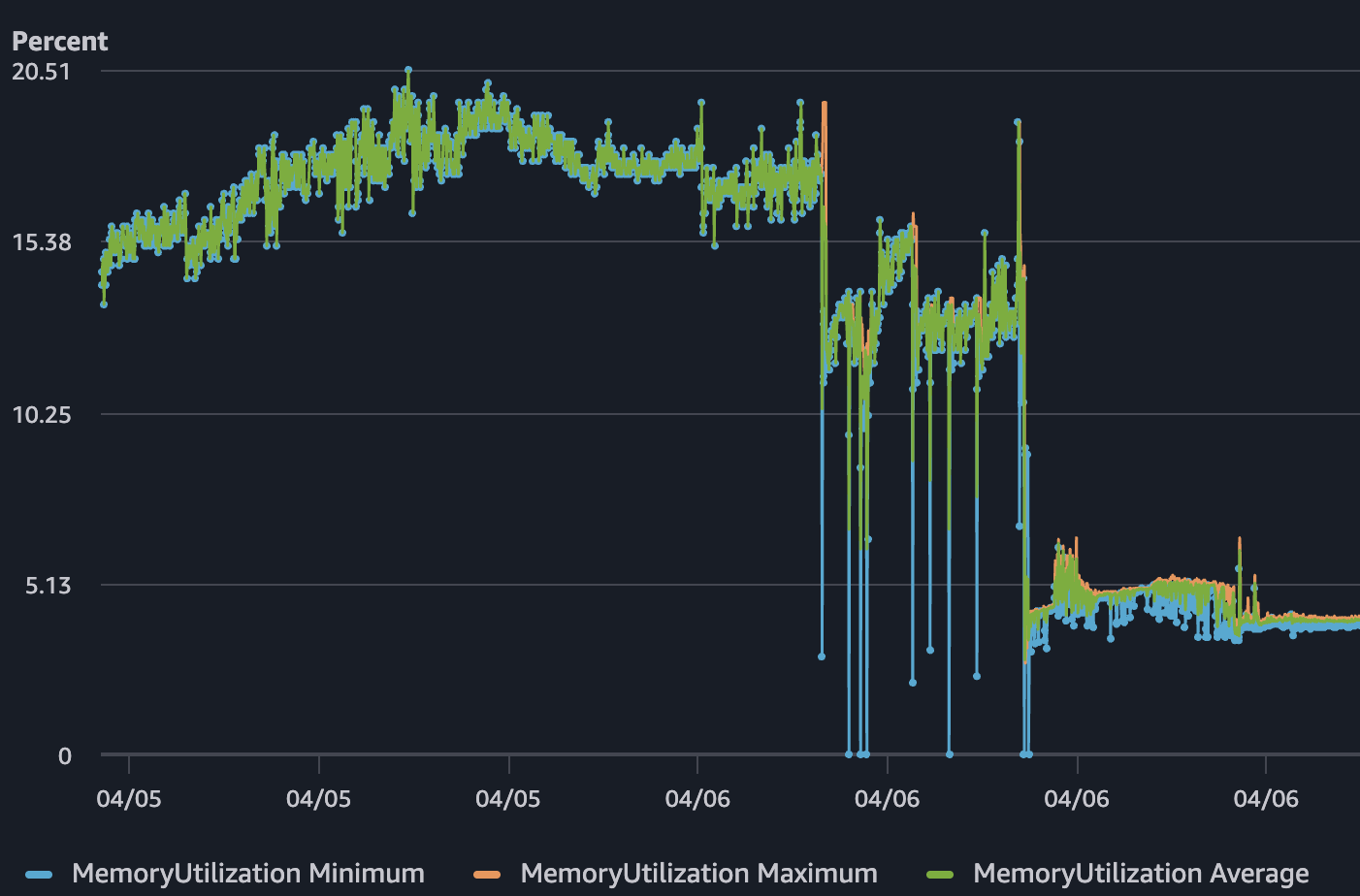
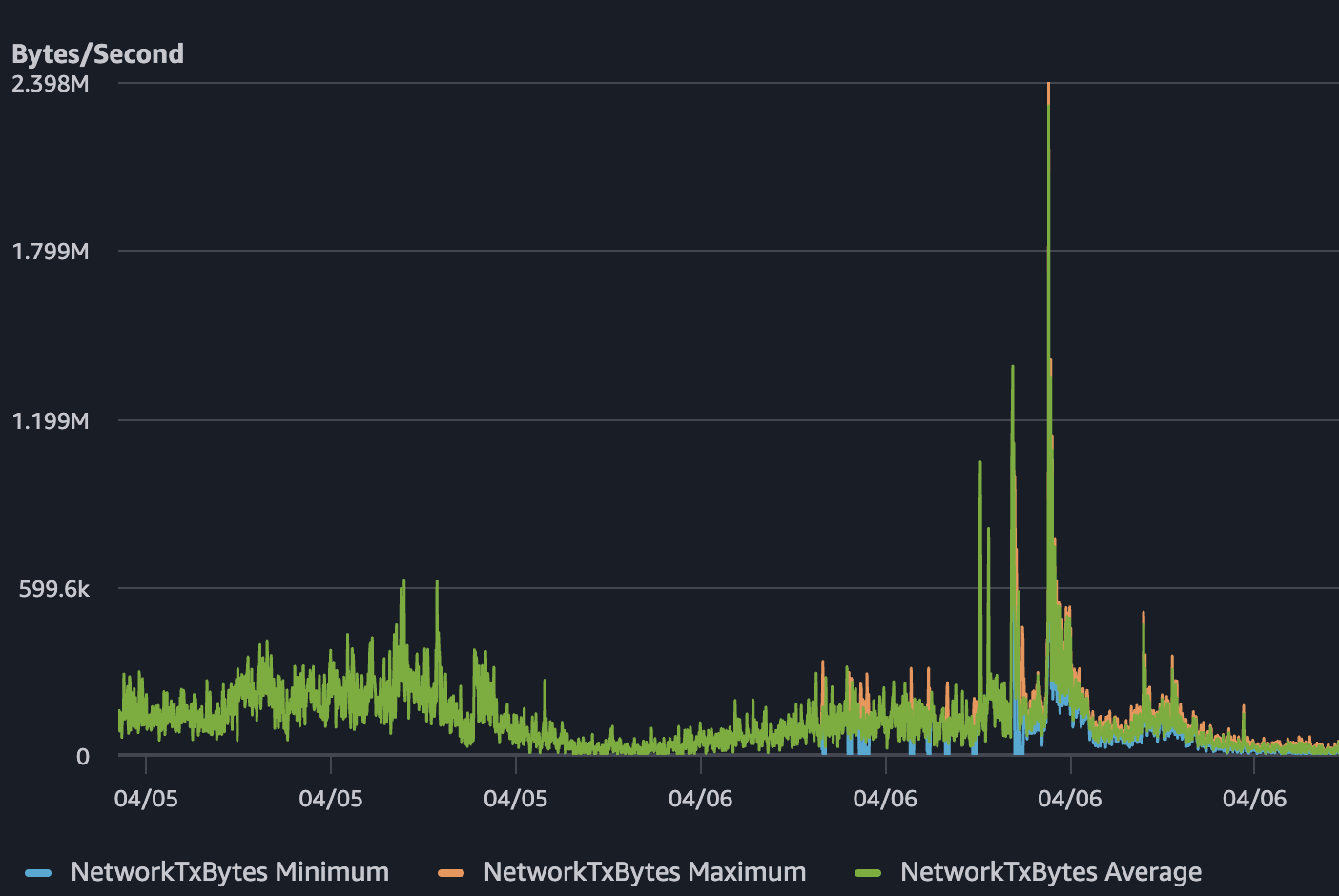
SSR이 실제 병목이었던 이유
문제는 SSR이 너무 넓게 적용되어 있었다는 데 있었다. 거의 기본값처럼 모든 페이지 요청에 SSR이 들어가 있었다. 요청이 들어올 때마다 서버에서 전체 렌더링 사이클을 돌리고, 컴포넌트 트리를 만들고, HTML을 Serialize해서 응답으로 내보냈다. 평소에는 이 비용이 크게 보이지 않았다. 애초에 대량의 트래픽이 몰릴 거라는 생각도 못 했고.
그런데 트래픽이 급증하자 그 비용이 그대로 드러났다. 요청 하나하나가 CPU 시간을 꽤 많이 잡아먹었고, 동시 요청이 많아지자 0.5 vCPU짜리 Task 3개로는 감당이 되지 않았다.
Auto Scaling이 왜 막아주지 못했나
Auto Scaling은 기본적으로 반응형이다. Metric을 보고, 임계값을 넘으면 용량을 늘리기로 결정하고, 새 Task를 띄우고, Health Check를 통과시킨 뒤, Load Balancer에 붙인다. 이 과정은 분 단위로 움직인다.
문제는 트래픽 급증은 그렇게 천천히 오지 않는다는 점이다. 초 단위로 몰리기 시작하면, 새 Task가 올라올 때쯤 기존 Task는 이미 포화 상태다. Auto Scaling은 나중에 용량을 더 보태줄 수는 있어도, 지금 당장의 무거운 요청들을 해결해주진 못한다. 모든 요청이 무겁다면 Task를 더 띄운다고 해도 문제를 몇 분 뒤로 미루는 것에 가까웠다.
뭘 바꿨나
해결책은 "컨테이너를 더 띄우자"가 아니었다. 먼저 요청당 불필요한 작업을 줄여야 했다.
어떤 페이지들이 실제로 SSR을 쓰고 있는지 다시 점검해보니, 생각보다 많은 라우트에서 SSR이 필요하지 않았다. 게임 자체는 완전히 Client Rendering으로 동작하는 인터랙티브 앱인데, 여러 페이지에서 SSR이 실질적인 이득 없이 비용만 추가하고 있었다. 그래서 필요 없는 곳의 SSR을 제거하고, 정적 렌더링이나 Client Rendering으로 전환했다. SSR이 정말 필요한 페이지는 그대로 남겨두되, 전체 요청 경로의 비용을 낮추는 쪽으로 정리했다.
별 것도 아닌 작업이었다. SSR이 기본값처럼 들어가 있던 부분을 하나씩 보고, 그 비용을 실제로 지불할 가치가 있는지 다시 따져보고, 필요 없으면 날려버렸다.
결과
변경 이후 차트의 차이는 꽤 바로 드러났다. 비슷한 수준의 트래픽이 들어왔을 때는 물론이고, 어떤 시점에는 이전보다 더 많은 트래픽이 들어왔는데도 CPU는 여유를 유지했다. 메모리는 더 낮아졌고, Network TX 패턴도 훨씬 안정적이었다. 서비스도 응답성을 유지했다.
전체 글