SSRがボトルネックになったとき
※ この記事は英語の原文をAIで翻訳したものです。
ECSサービスにはauto scalingを有効にしていました。タスク3つ稼働中、health check通過、load balancerのターゲットも全部グリーン。システム上はトラフィック急増に備えた状態でした。しかし4月6日、トラフィックが急増し、サービスはそのまま崩れました。
「スケール可能」と「急増に耐えられる」は別の話です。
チャートが示したもの
apple-game-v2クラスターのwebサービスのECSダッシュボードに全体像が出ていました。3タスク全て稼働中。load balancerターゲット3つとも正常。プラットフォーム側から見れば、全て正常でした。
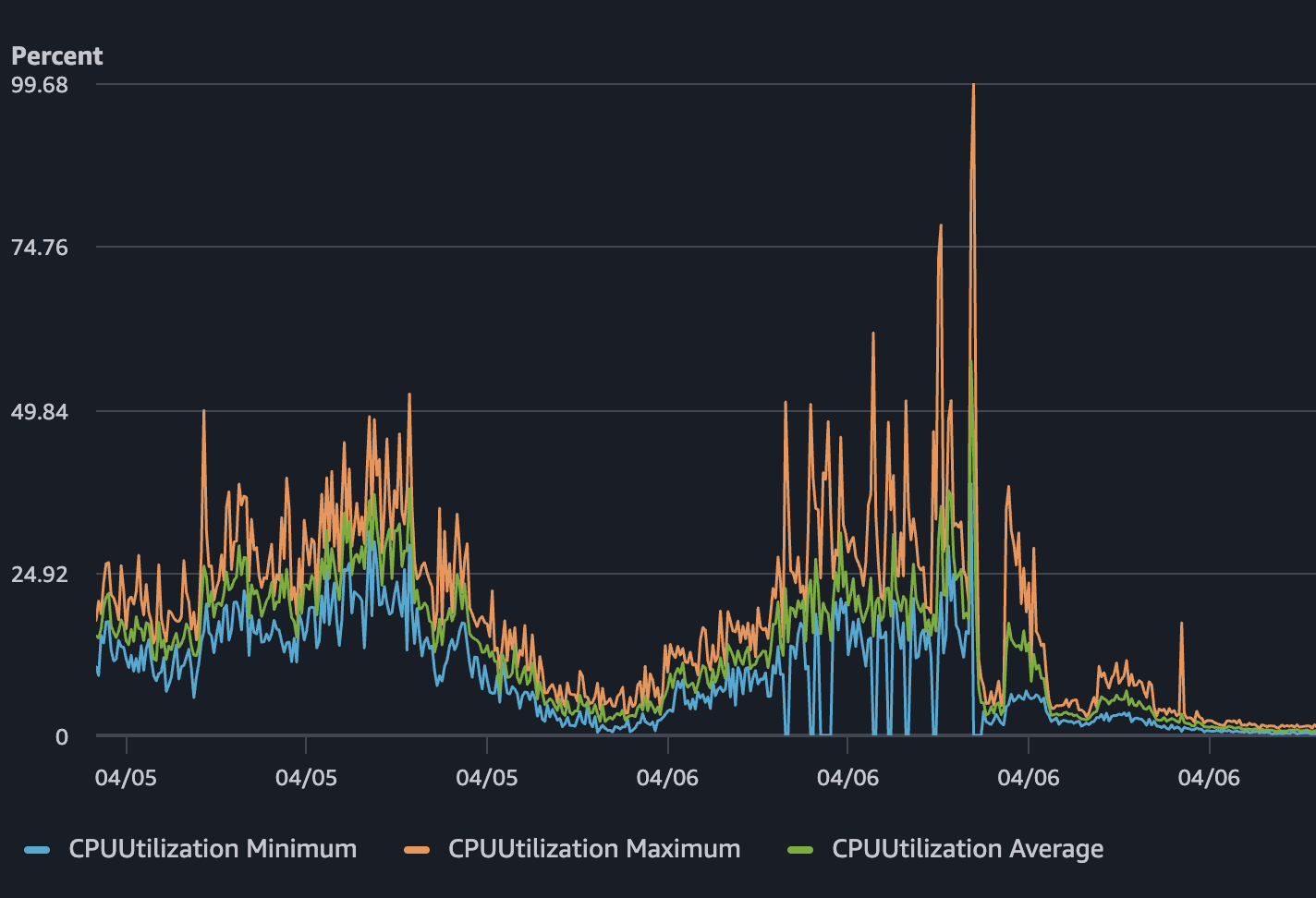
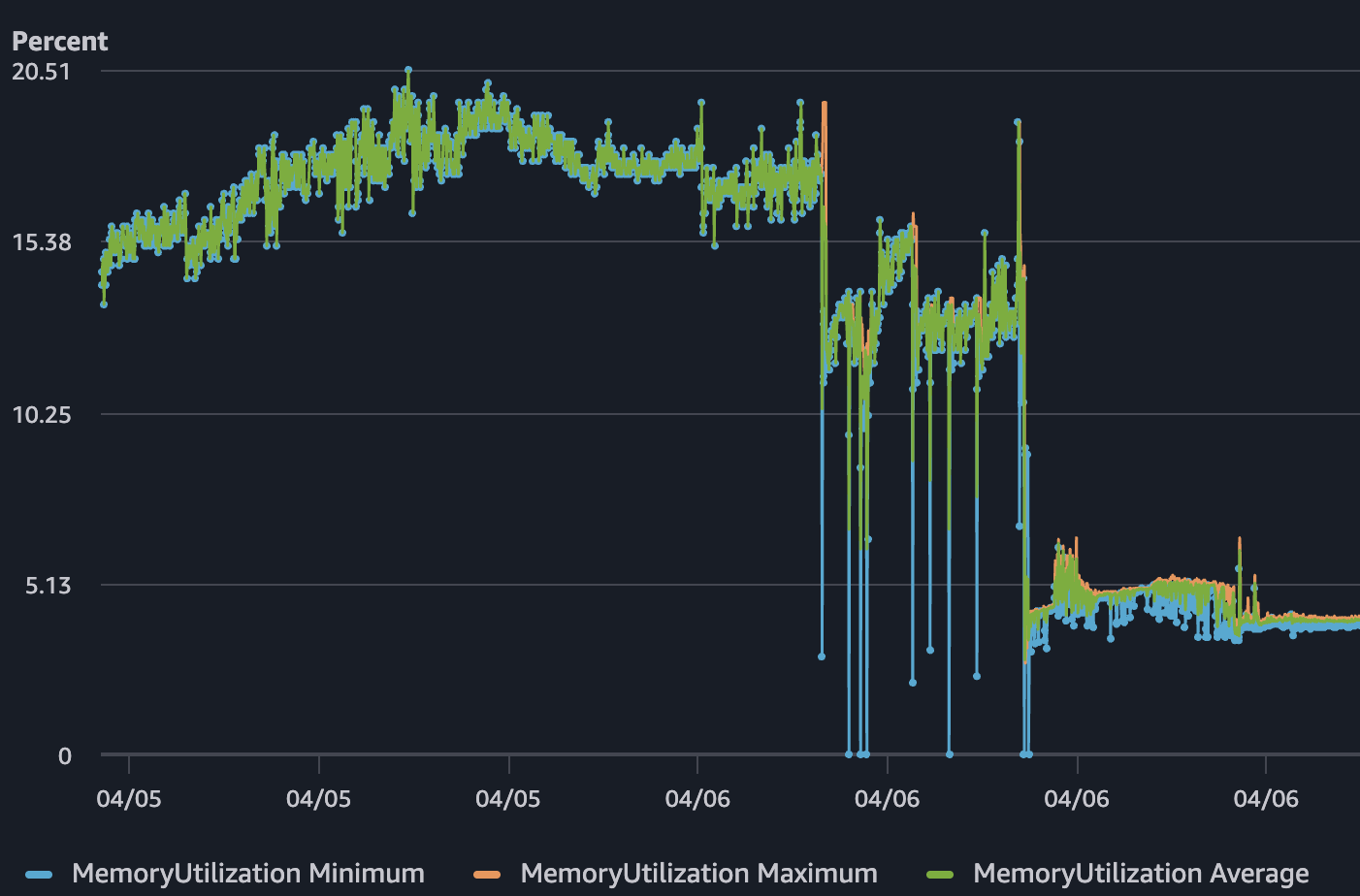
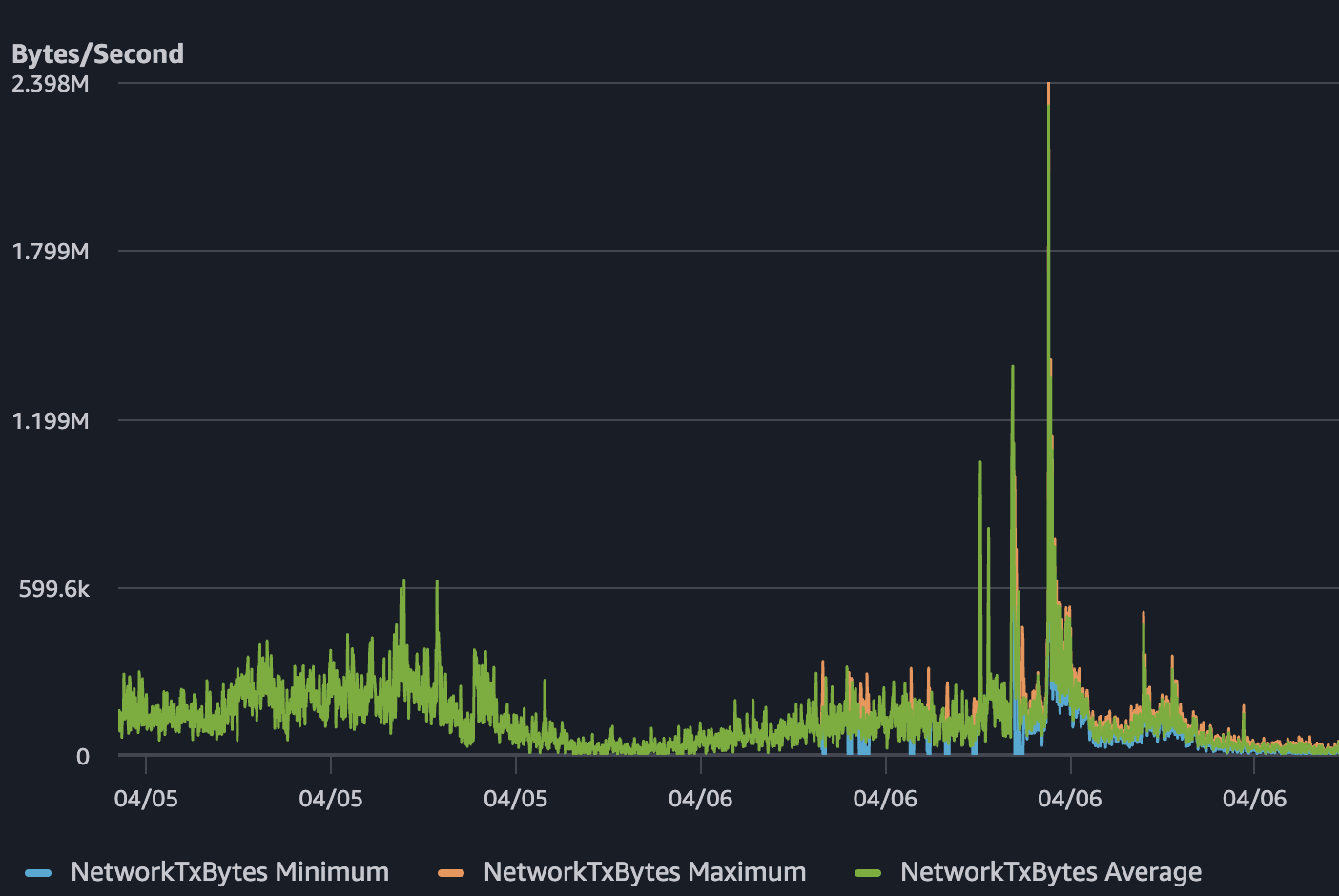
しかし4月6日、CPU使用率が100%近くまで跟ね上がりました。Network TXは約2.4 MB/sまで跳ねました。メモリは10%台半ばでボトルネックではありませんでした。サービス自体は生きていましたが、息ができない状態でした。ユーザーは遅いレスポンスやタイムアウトを経験しているのに、health checkはずっと正常と報告し続けていました。
SSRが本当のボトルネックだった理由
SSRが広く適用されすぎていました - ほぼデフォルトのように。すべてのページリクエストがサーバーでフルレンダリングサイクルを回していました。コンポーネントツリーの構築、HTMLのシリアライズ、送信まで。これをタダだと思っていました。そうではありませんでした。
通常のトラフィックではこのコストは見えませんでした。しかし急増が来ると、それが問題の全てになりました。SSRリクエスト一つ一つが相応のCPU時間を食い、同時リクエストが十分に增えると、0.5 vCPUのタスク3つでは余裕がありませんでした。CPUグラフは嘘をつきません - ワークロードは実際にリクエストごとにそれだけかかっていたのです。
auto scalingがなぜ救えなかったのか
Auto scalingはリアクティブです。メトリクスを監視し、閾値を超えたら容量を追加することを決め、新しいタスクを起動し、health checkを待ち、load balancerに登録します。このプロセスは分単位ですが、トラフィック急増は秒単位で起きます。新しいタスクが立ち上がる頃には、既存のタスクはもう飽和状態です。Auto scalingは後から容量を追加できますが、今まさにコストの高いリクエストパスを消すことはできません。すべてのリクエストが高コストなら、タスクを増やしても問題が数分後にずれるだけです。
何を変えたか
解決策は「コンテナを増やす」ではありませんでした。リクエストごとの不要な作業を減らすことでした。
どのページが実際にSSRを使っているか監査したところ、ほとんどが必要ありませんでした。ゲーム自体が完全にクライアントレンダリングのインタラクティブアプリで、ほとんどのルートでSSRは意味のあるメリットなくコストだけ追加していました。不要な箇所のSSRを削除し、静的またはクライアントサイドレンダリングに切り替えました。SSRが本当に必要なページはそのまま残しましたが、全体のリクエストパスのコストは大幅に下がりました。
リライトではありませんでした。実用的な削減です - SSRがデフォルトで適用されていた箇所を見つけ、実際にそのコストに見合う価値があるかを問い直したものです。
結果
変更後、チャートの差は即座に現れました。同程度のトラフィックが来たとき - むしろ以前より多いこともありましたが - CPUは飽和点を大きく下回りました。メモリはさらに下がり、Network TXパターンも正常でした。サービスは終始レスポンシブを維持しました。
必要のないコードを削除するだけでした。
投稿一覧