사과게임 점수에 실제로 영향을 주는 것은 무엇일까?
사과게임을 어느 정도 해봤다면, 어떤 보드는 유난히 어렵게 느껴지고 어떤 보드는 훨씬 잘 풀린다는 걸 체감했을 것이다. 어떤 판은 술술 풀려서 거의 다 지우게 되지만, 어떤 판은 아무리 해도 숫자가 잘 맞지 않는다. 그런데 이게 단순한 느낌의 문제일까, 아니면 실제로 점수를 예측하는 보드의 특성이 있을까? 이를 확인하기 위해 여러 후보 지표를 비교해봤다.
비교를 일관되게 하기 위해 모든 보드는 단순한 Greedy Solver로 점수를 매겼다. 이 Solver는 완벽하지는 않지만, 모든 보드에 같은 전략을 적용하기 때문에 비교 기준으로는 충분히 공정하다. 이 글에서는 Solver 자체보다 지표에 집중한다. 어떤 Feature가 점수와 상관이 있었고, 어떤 것은 그렇지 않았는지를 본다.
가장 강한 신호: 보드 전체 합
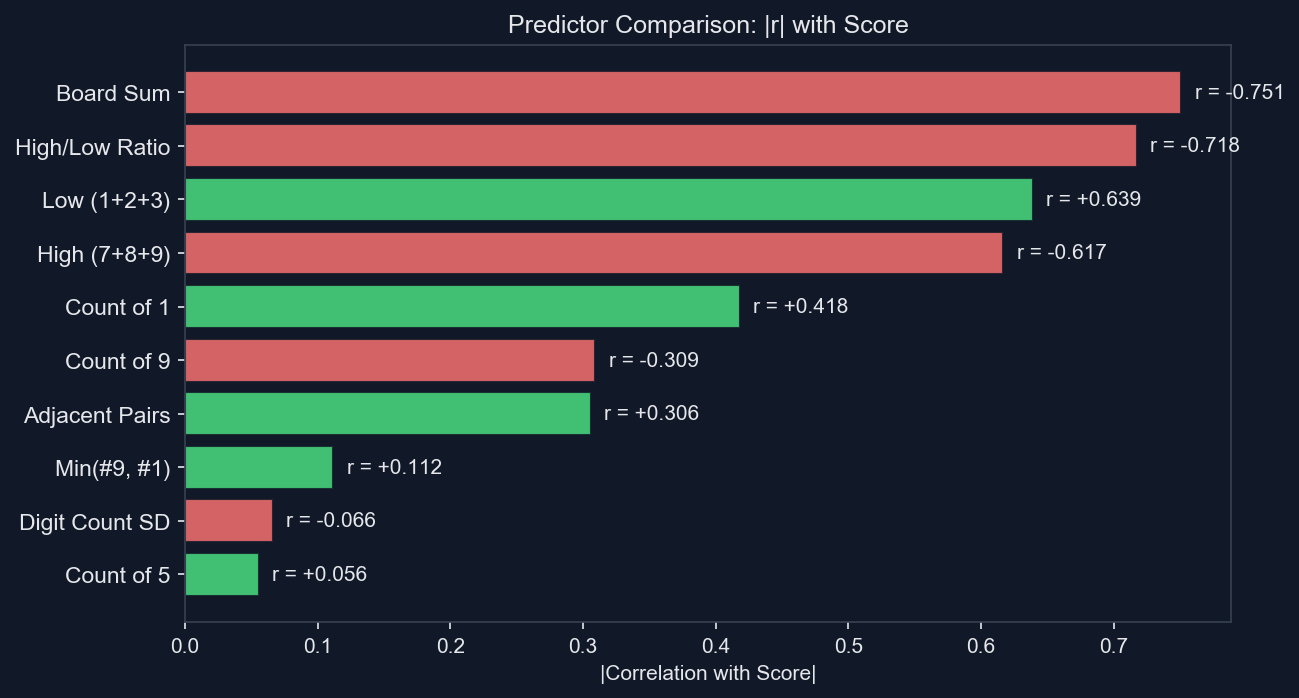
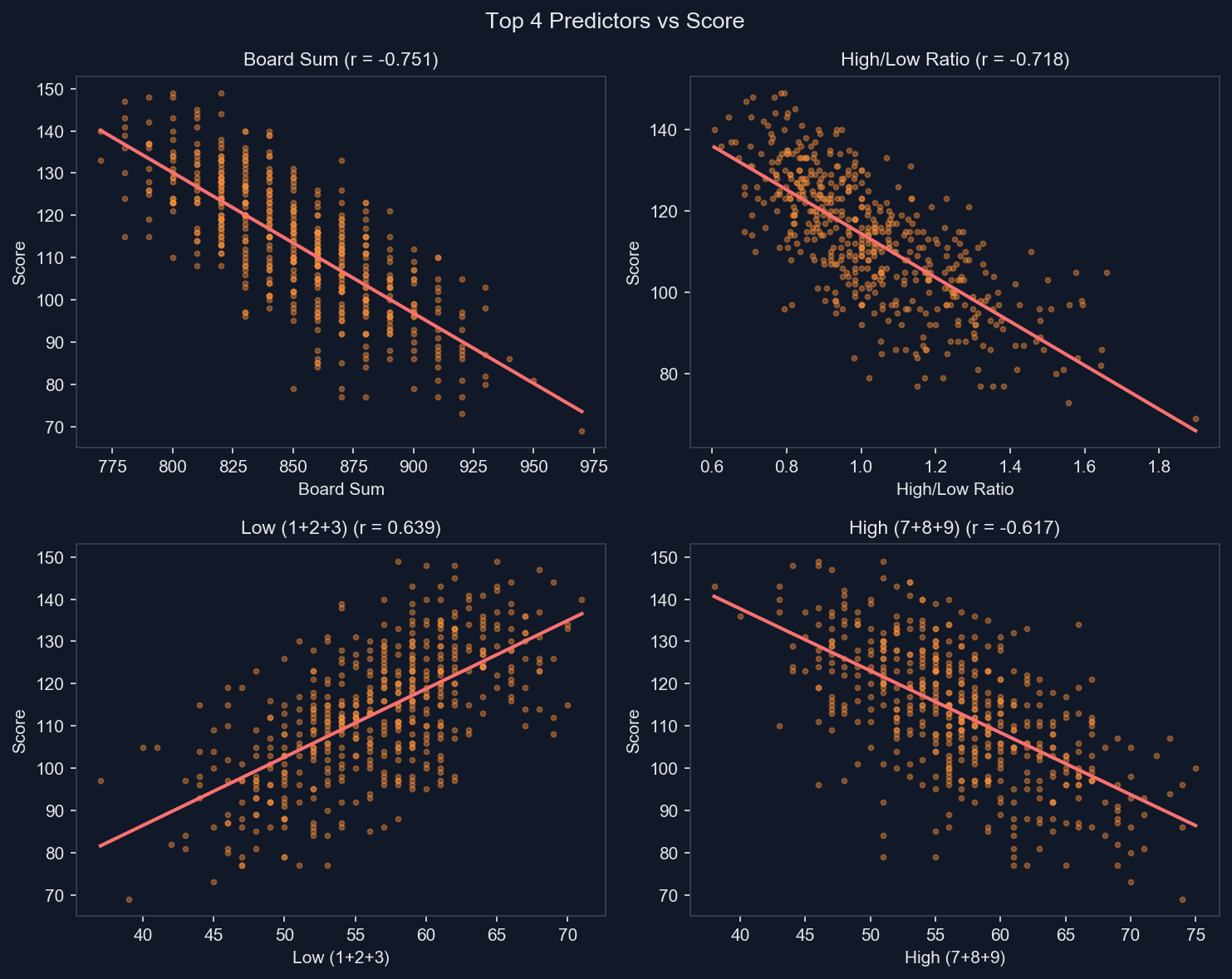
테스트한 지표들 가운데, 보드에 있는 모든 숫자의 총합이 점수를 예측하는 가장 강한 단일 지표였다. 상관은 꽤 강한 음의 방향으로 나타났고(r ≈ -0.75), 보드 전체 합이 높을수록 점수는 일관되게 낮아졌다.
보드 전체 합이 높다는 것은 7, 8, 9 같은 큰 숫자가 더 많이 퍼져 있다는 뜻이다. 큰 숫자는 10을 만들기 위해 그에 맞는 작은 숫자가 필요하기 때문에 처리하기가 더 어렵다. 그런데 그런 작은 숫자가 가까이에 없을 수도 있고, 이미 다른 곳에서 소모됐을 수도 있다. 그 결과, 전체 합이 높은 보드는 끝까지 지워지지 않는 셀이 더 많이 남고, 최종 점수도 낮아진다.
이 한 숫자, 즉 보드의 모든 값을 그냥 더한 값이, 우리가 시도한 어떤 다른 지표보다도 기대 점수에 대한 정보를 더 많이 담고 있었다.
그 외에도 강한 지표들
몇몇 다른 Feature도 점수와 상관이 있었지만, 단독으로는 보드 전체 합만큼 강하지는 않았다.
7, 8, 9 같은 높은 숫자와 1, 2, 3 같은 낮은 숫자의 비율은 꽤 강한 차선 지표였다. 높은 숫자가 많은 보드는 성능이 나빴고, 낮은 숫자가 많은 보드는 더 잘 풀렸다. 이와 비슷하게, 낮은 숫자(1, 2, 3)의 개수는 점수와 양의 상관을 보였고, 높은 숫자(7, 8, 9)의 개수는 음의 상관을 보였다. 낮은 숫자가 많을수록 더 유연하게 조합할 수 있기 때문이다.
조금 더 들어가 보면, 보드 위의 1의 개수와 9의 개수도 각각 눈에 띄는 영향을 보였다. 1은 가장 다루기 쉬운 숫자다. 9와 짝을 이룰 수 있고, 숫자 자체가 작아서 보드 전체 합도 낮게 유지해준다. 반대로 9는 그 반대다. 전체 합을 끌어올리고, 짝으로 1을 요구하며, 대체로 가장 처리하기 어려운 숫자다. 이런 개별 숫자 개수도 의미는 있지만, 결국 보드 전체 합의 구성 요소이기 때문에 전체 합이 더 좋은 종합 지표로 남는다.
의외로 약했던 지표들
처음에는 중요할 것 같았지만, 실제로는 예상보다 약했던 지표들도 있었다.
처음 보드에서 인접한 두 숫자의 합이 10이 되는 쌍의 개수, 즉 눈에 바로 보이는 쉬운 수의 개수는 중간 정도의 예측력만 보였다. 직관적으로는 이런 쌍이 많으면 쉬운 보드일 것 같지만, 초반에 쉬운 수가 많다고 해서 이후 보드까지 잘 풀린다는 보장은 없다. 시작은 쉬워 보여도, 몇 번 지우고 나면 남은 숫자들이 도무지 맞지 않는 형태로 꼬여버릴 수 있다.
5의 개수도 생각보다 약한 지표였다. 5는 두 개만 있어도 10이 되니, 5가 많은 보드는 잘 풀릴 것처럼 보일 수 있다. 하지만 실제로 5는 꽤 중립적인 숫자다. 평균적인 숫자 크기와 비교했을 때 보드 전체 합을 특별히 올리지도 내리지도 않고, 5는 결국 5와만 짝을 이룰 수 있어서 유연성도 제한적이다.
각 숫자가 얼마나 고르게 분포하는지를 나타내는 Digit-count Standard Deviation도 상관이 크지 않았다. 숫자가 아주 균등하게 퍼져 있다고 해서 자동으로 점수가 잘 나오는 것은 아니다. 반대로 숫자 분포가 치우쳐 있어도, 그 치우침이 작은 숫자 쪽이라면 충분히 잘 풀릴 수 있다.
이 결과가 말해주는 것
패턴은 꽤 분명하다. 점수는 초반에 눈에 보이는 쉬운 기회보다, 보드 전체의 숫자 구성이 어떻게 생겼는지에 더 크게 좌우된다. 당장 보이는 인접 Pair의 개수 같은 Local Feature는 노이즈가 많은 지표였다. 반면 큰 숫자와 작은 숫자의 균형처럼 보드 전체를 보는 Global Feature는 훨씬 더 안정적으로 점수를 설명했다.
Greedy Solver든 사람 플레이어든, 눈에 띄는 쉬운 수는 어차피 어느 정도는 처리하게 된다. 최종 점수를 가르는 것은 그런 쉬운 수를 지운 다음에 무엇이 남느냐이다. 그리고 그 남은 구조는 결국 보드 전체의 숫자 구성에 의해 크게 결정된다.
가장 강한 신호는 의외로 가장 단순한 지표에서 나왔다. Local Pattern보다 전체 구성이 더 중요했고, 보드의 모든 숫자를 더한 총합이 그 판이 얼마나 어려울지를 알려주는 가장 좋은 단서였다. 보드를 슬쩍 봤는데 7, 8, 9가 많이 보인다면, 꽤 고전할 가능성이 높다. 반대로 1, 2, 3이 많다면 상대적으로 운이 좋은 판일 가능성이 크다.
전체 방법론과 데이터는 난이도 분석 연구 전문에서 확인할 수 있다.
전체 글