Rejection Sampling이란?
사과게임을 하다 보면 한 가지 흥미로운 점이 있다. 보드는 분명 무작위처럼 보이는데, 전체 숫자의 합은 항상 10의 배수라는 제약을 만족한다. 이런 식으로 무작위성은 유지하면서도 특정 조건을 만족하는 데이터는 어떻게 만들 수 있을까? 그때 떠올릴 수 있는 가장 단순한 방법 중 하나가 Rejection Sampling이다.
이 방법은 사과게임에만 쓰이는 특수한 기법은 아니다. 제약 조건이 있는 무작위 샘플을 만들어야 할 때 여러 곳에서 등장하는, 꽤 범용적인 아이디어다.
핵심 아이디어
Rejection Sampling은 특정 조건을 만족하는 무작위 샘플을 만드는 방법이다. 방식은 아주 단순하다. 먼저 샘플링하기 쉬운 분포에서 후보를 하나 만든다. 그다음 그 후보가 원하는 조건을 만족하는지 확인한다. 만족하면 채택하고, 만족하지 않으면 버린 뒤 다시 뽑는다.
이게 전부다.
즉, 제약이 걸린 최종 분포에서 직접 샘플링하는 복잡한 방법을 설계할 필요가 없다. 필요한 것은 두 가지뿐이다. 후보를 생성하는 방법과 그 후보가 조건을 만족하는지 검사하는 방법이다.
알고리즘
function RejectionSample(Generate, Satisfies): Sample; var candidate: Sample; begin repeat candidate := Generate(); until Satisfies(candidate);
RejectionSample := candidate; end;
과정을 말로 풀면 더 간단하다. 무작위 후보를 하나 만든다. 조건을 검사한다. 통과하면 사용한다. 통과하지 못하면 버리고 다시 시도한다. 각 시도는 이전 결과와 무관하므로, 이 과정은 무기억(memoryless)한 반복으로 볼 수 있다.
예시
원 안의 점 샘플링. 가장 전형적인 예시는 원 안의 점을 샘플링하는 경우다. 단위원 내부에서 균일한 무작위 점을 얻고 싶다고 해보자. 원 내부에서 직접 점을 뽑는 방법을 따로 설계할 수도 있지만, 더 단순한 방법이 있다. 원을 감싸는 정사각형 안에서 먼저 점을 하나 무작위로 뽑고, 그 점이 원 안에 들어오는지만 검사하면 된다.
예를 들어 x와 y를 각각 -1에서 1 사이에서 균일하게 뽑은 뒤, x² + y² ≤ 1인지 확인한다. 이 조건을 만족하면 채택하고, 아니면 버리고 다시 뽑는다.
이 방식이 실용적인 이유는 Acceptance Rate가 꽤 높기 때문이다. 단위원의 넓이는 외접 정사각형 넓이의 약 78.5%이므로, 대략 다섯 번 중 네 번은 통과한다. 버려지는 샘플이 있긴 하지만, 그 정도면 충분히 효율적이다.
유효한 비밀번호 생성. 또 다른 예시는 규칙이 있는 무작위 비밀번호 생성이다. 예를 들어 대문자, 숫자, 특수문자가 각각 최소 하나씩 포함되어야 한다고 하자. 이때 한 가지 방법은 전체 문자 집합에서 원하는 길이만큼 문자열을 무작위로 만든 뒤, 규칙을 만족하는지 검사하는 것이다. 조건을 만족하면 채택하고, 아니면 버리고 다시 생성한다.
비밀번호 길이가 충분히 길다면 대부분의 후보가 규칙을 통과하므로, 이런 방식도 실용적으로 잘 동작한다. 굳이 복잡한 생성 로직을 따로 짜지 않아도 되는 셈이다.

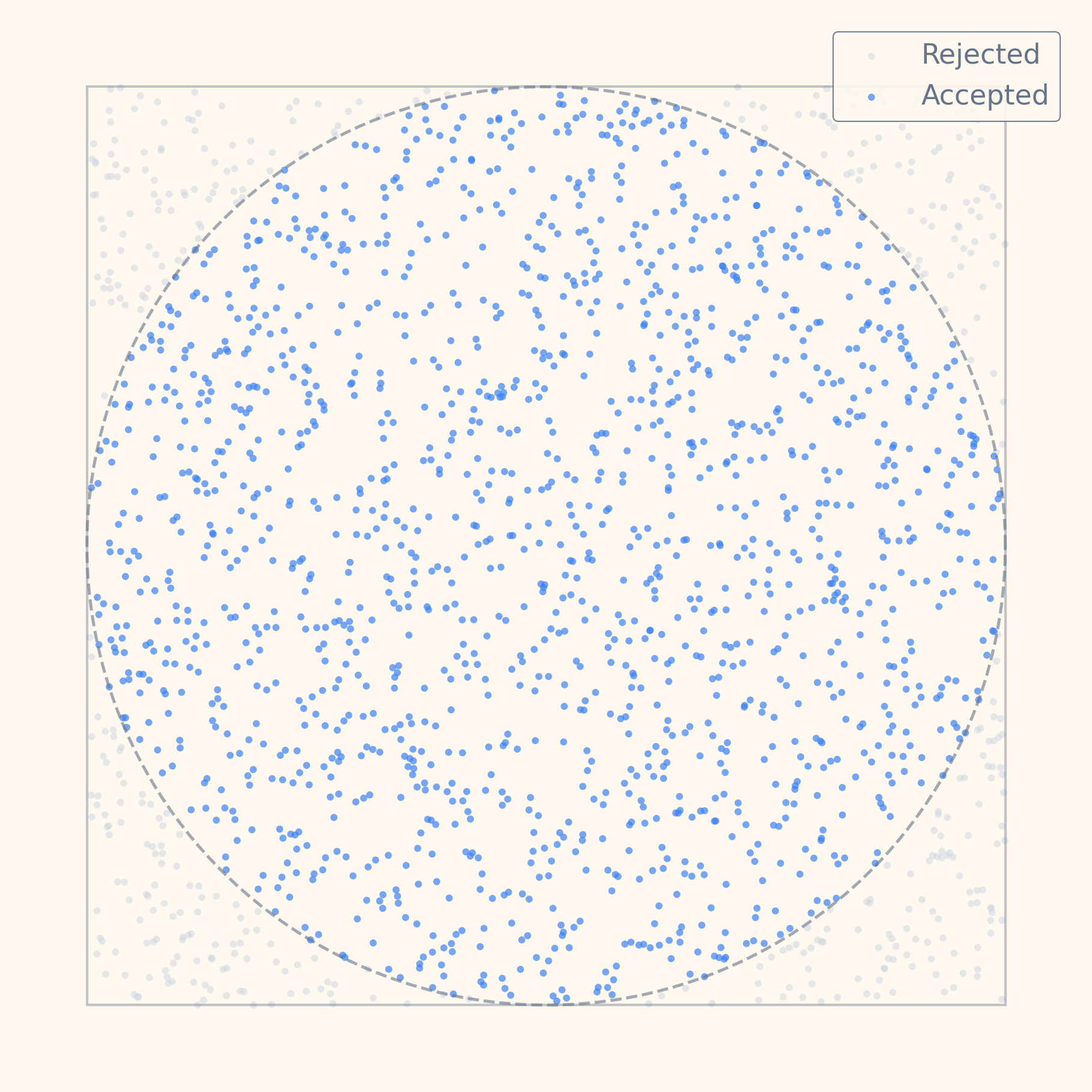
사각형에서 균일하게 샘플링된 무작위 점들. 원 안의 점은 채택(파란색), 외부의 점은 버려짐(회색).
왜 유용한가
Rejection Sampling의 가장 큰 장점은 단순함이다. 제약 조건이 있는 분포를 직접 다루는 특수한 알고리즘을 만들지 않아도 된다. 후보를 생성할 수 있고, 그 후보가 조건을 만족하는지 검사할 수만 있으면 된다. 구현도 보통은 난수 생성과 조건 검사, 그리고 반복문 정도로 끝난다.
특히 조건을 검증하는 일은 쉽지만, 그 조건을 생성 과정에 직접 녹여 넣기는 어려운 경우에 유용하다. 현실의 문제 중에는 이런 형태가 꽤 많다. 그래서 Rejection Sampling은 이론적으로도 자주 등장하고, 실제 구현에서도 먼저 떠올려볼 만한 방법이 된다.
주요 한계: Acceptance Rate
물론 이 방법이 항상 좋은 것은 아니다. Rejection Sampling이 잘 작동하려면, 생성한 후보 중에서 꽤 많은 비율이 실제로 조건을 통과해야 한다. 여기서 핵심이 되는 값이 Acceptance Rate다. 즉, 무작위로 만든 후보가 유효한 샘플일 확률이다.
Acceptance Rate가 10%라면, 샘플 하나를 얻기 위해 평균적으로 10번 정도 시도하면 된다. 이 정도는 충분히 감당 가능하다. 하지만 Acceptance Rate가 0.0001% 수준이라면 이야기가 완전히 달라진다. 유효한 샘플 하나를 얻기 위해 엄청난 수의 후보를 버려야 하고, 계산량 대부분이 낭비된다.
고차원 문제에서는 이런 일이 더 자주 생긴다. 예를 들어 아주 높은 차원의 공간에서 작은 영역 하나를 목표로 샘플링해야 한다면, 외접하는 큰 공간에서 무작위 후보를 만드는 방식은 거의 대부분 실패로 끝난다. 이런 상황에서는 Rejection Sampling이 급격히 비효율적이 되고, 결국 다른 방법을 고려해야 한다. MCMC나 Importance Sampling 같은 기법이 필요한 경우가 여기에 해당한다.
실무 감각으로 말하면, Acceptance Rate가 어느 정도 괜찮게 나오는 경우에는 Rejection Sampling이 좋은 첫 번째 선택이 될 수 있다. 반대로 Acceptance Rate가 지나치게 낮다면, 단순함이라는 장점보다 비효율이 더 크게 드러난다.
다시 사과게임으로
사과게임으로 돌아가 보면, 무작위로 생성한 보드가 전체 합이 10의 배수라는 조건을 만족할 확률은 대략 10분의 1 정도다. 즉, Acceptance Rate가 약 10% 수준이라는 뜻이다. 이 정도면 Rejection Sampling을 쓰기에 꽤 괜찮은 편이다. 평균적으로 몇 번만 다시 뽑으면 조건을 만족하는 보드를 얻을 수 있기 때문이다.
전체 글